Pensemos, no seguinte problema: uma versão simplificada da simulação apresentada por Colquhoun (2014), cujo código fonte do script foi disponibilizado para reprodução.
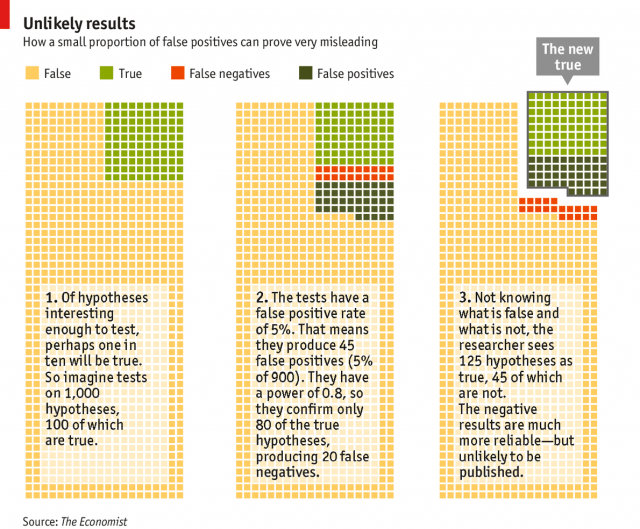
Em um determinado campo, um total de mil hipóteses estão sendo investigadas. Estabelecemos arbitrariamente que, dentre essas, 100 refletem relações verdadeiras presentes na realidade, ainda que ninguém saiba quais sejam. Digamos que os experimentos, quando diante das hipóteses verdadeiras, identifiquem 80% delas. Neste caso, a taxa de falso-negativo β é de 20%. Imaginemos uma taxa de falso-positivo α mais baixa, de apenas 5%. Como temos um grande número de hipóteses falsas a serem testadas, o que é natural, descartamos corretamente 855 hipóteses falsas, mas geramos 45 falsos positivos.
A nova verdade estabelecida neste campo compreenderá 125 hipóteses alternativas, das quais mais de um terço é falsa. Desta forma, mesmo seguindo-se todos os procedimentos padrões, quase um terço das descobertas anunciadas são falsas.
Algumas soluções foram apresentadas por estatísticos para que esses enganos sejam sanados. Uma delas é a adoção de valores de p mais baixos, como é o caso da física de partículas, que adota o valor de p = 0.0000003, o que também é conhecido como cinco sigma.
Neste caso, os erros de falso positivo seriam muito mais raros do que quando se adota o p valendo 0.5. A probabilidade de que, com a hipótese nula verdadeira os resultados obtidos, ou outros mais extremos, teoricamente será de 1 em 3,5 milhões.
A própria ideia de certeza probabilística, se tomada mecanicamente, como comumente o é, pode ser considerada uma aporia. Pela própria natureza do conhecimento estatístico, ele nunca é livre de erro, ainda que teoricamente (e em alguns casos muito excepcionais) possamos fazer com que a possibilidade de um erro seja tão remota que não fosse plausível sua ocorrência, nem que o nosso universo fosse de ordens de magnitude mais velho do que se acredita que ele seja. Contudo, os modelos com os quais os pesquisadores lidam na prática sempre contêm a possibilidade real da ocorrência de dois tipos de erros que coexistem em uma relação dialética.
O Erro de tipo 1, também conhecido como falso-positivo, ocorre quando a hipótese nula (H0) é verdadeira, mas a rejeitamos. Dessa forma enxergamos uma relação que não existe na realidade. O Erro de tipo 2, ou falso-negativo, ocorre quando a hipótese nula (H0) é falsa, mas não é rejeitada. Isso significa que deixamos de perceber uma relação presente na realidade. As taxas de erros dos tipos 1 e 2 são denominadas, respectivamente, α e β. Apesar de muitas vezes serem tomadas como tal, nenhuma delas é o valor-p.
Um dos equívocos conceituais acerca do valor-p é de que este seria a probabilidade da hipótese nula de um teste ser verdadeira, ou a probabilidade de um dado resultado ter sido obtido por acaso, ou mesmo que o valor-p seria a probabilidade da hipótese nula ter sido equivocadamente rejeitada.
De forma bem objetiva, o valor-p é a probabilidade do resultado obtido, ou algum mais extremo que ele (no sentido de reforçar a correlação) ter sido obtido dado que a hipótese nula seja verdadeira1. Desta forma, se o valor de p, que é calculado apenas ao final do experimento, de posse de todos os dados, for baixo, isso deve significar duas coisas: ou que a hipótese nula é verdadeira e que um evento altamente improvável ocorreu (gerando um falso-positivo), ou que a hipótese nula é falsa (confirmação da hipótese alternativa). O quão improvável é este falso positivo e se a resposta para essa questão está toda contida dentro do modelo matemático é um dos dilemas associados à Crise Estatística.
Se aumentarmos a sensibilidade da nossa detecção, de forma a minimizar a ocorrência de erros de falso-negativo (tipo 2), no qual deixarmos de perceber uma relação existente, consequentemente aumentaremos a incidência de erros de falso-positivo (tipo 1), no qual enxergamos uma relação quando ela não está presente na realidade. Se diminuirmos a sensibilidade, teremos menos erros de falso-positivo (tipo 1), mas deixaremos passar um número maior de efeitos não percebidos, logo, um aumento dos erros de falso-negativo (tipo 2).
Essa calibração do experimento pode se dar de várias formas, seja efetivamente calibrando um sensor de detecção em um equipamento, seja matematicamente, estabelecendo os tipos de controle de erros. Por exemplo, se for apresentado, para decidir se foi forjado ou efetivamente aleatório, que o resultado de 40 lances de uma moeda seja uma série com 20 caras seguidas depois de 20 coroas, pode-se chutar, com uma grande probabilidade de acerto, que este resultado não foi efetivamente gerado por um processo aleatório. Poderíamos excluir tal resultado das nossas medições, mas, mesmo pertencendo a um conjunto raro de resultados, ele em si é tão possível quanto qualquer outro resultado.
No caso de exames de detecções de doenças, como o HIV, a calibração é favorável à ocorrência de erros de tipo 1, pois é preferível dar uma notícia ruim erroneamente a uma pessoa que ao final descobrirá com testes confirmatórios (que fazem parte do protocolo) não ter a doença, do que deixar de detectar a doença em uma pessoa que precisa de tratamento.
1Existe uma diferença de interpretação sobre o significado do valor-p de acordo com o modelo de teste de hipóteses escolhido, o modelo de Neyman-Pearson, ou o de Fisher. Trata-se de um dissenso que perdura há décadas que tem como base uma questão filosófica acerca do papel dos modelos em inferência estatística. A base da controvérsia é a relação entre probabilidade e estatística. Os livros-texto atualmente utilizam um modelo híbrido dos dois métodos, mas esta alternativa também é alvo de críticas, por serem as duas abordagens incongruentes entre si.

Comentários